BEACON
Milestone-Guided Policy Learning for Long-Horizon Language Agents
†Corresponding author: syl@zju.edu.cn
ICML 2026
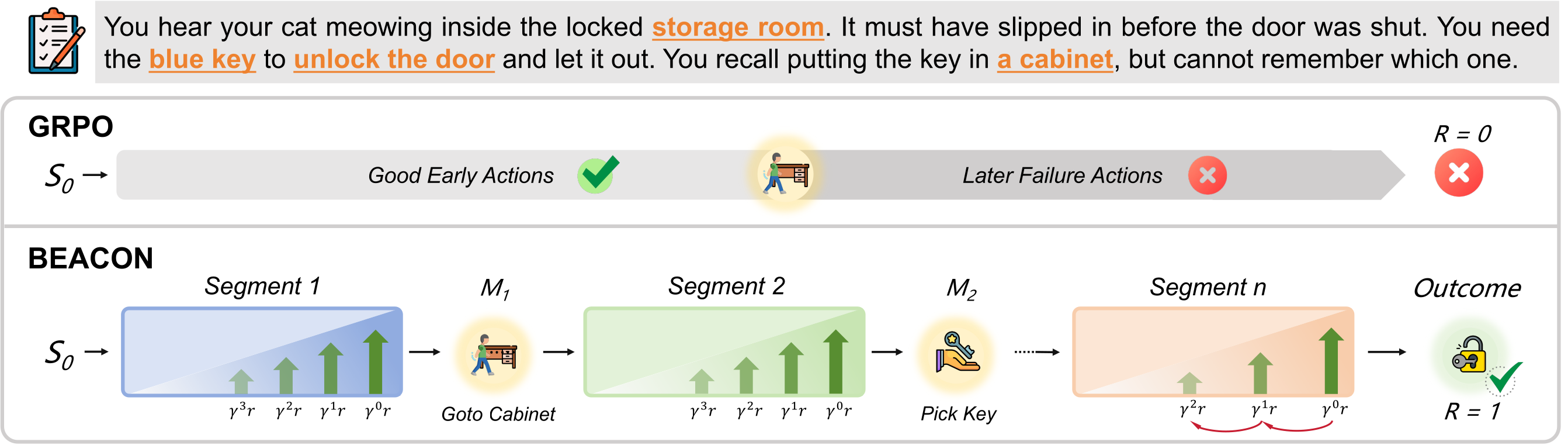
While long-horizon agentic tasks require language agents to perform dozens of sequential decisions, training such agents with reinforcement learning remains challenging. We identify two root causes: credit misattribution, where correct early actions are penalized due to terminal failures, and sample inefficiency, where scarce successful trajectories result in near-total loss of learning signal.
We introduce a milestone-guided policy learning framework, BEACON, that leverages the compositional structure of long-horizon tasks to ensure precise credit assignment. BEACON partitions trajectories at milestone boundaries, applies temporal reward shaping within segments to credit partial progress, and estimates advantages at dual scales to prevent distant failures from corrupting the evaluation of local actions.
On ALFWorld, WebShop, and ScienceWorld, BEACON consistently outperforms GRPO and GiGPO. Notably, on long-horizon ALFWorld tasks, BEACON achieves 92.9% success rate, nearly doubling GRPO's 53.5%, while improving effective sample utilization from 23.7% to 82.0%. These results establish milestone-anchored credit assignment as an effective paradigm for training long-horizon language agents.
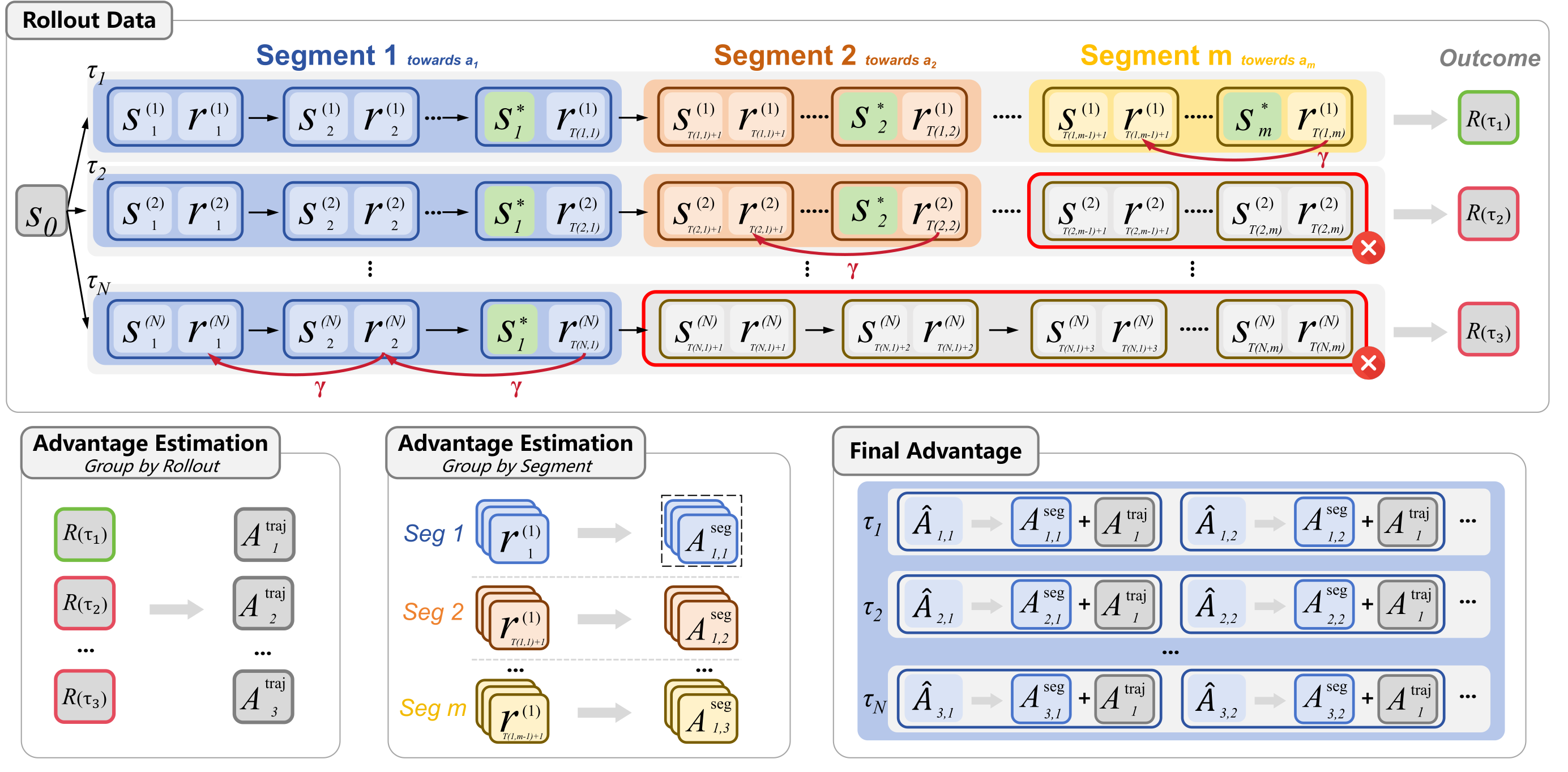
The BEACON framework. Top: trajectory partitioning at milestone boundaries with temporal reward decay (factor γ). Bottom: dual-scale advantage estimation combining trajectory-level and segment-level signals.
BEACON operates in three stages:
subgoal_completed directly.
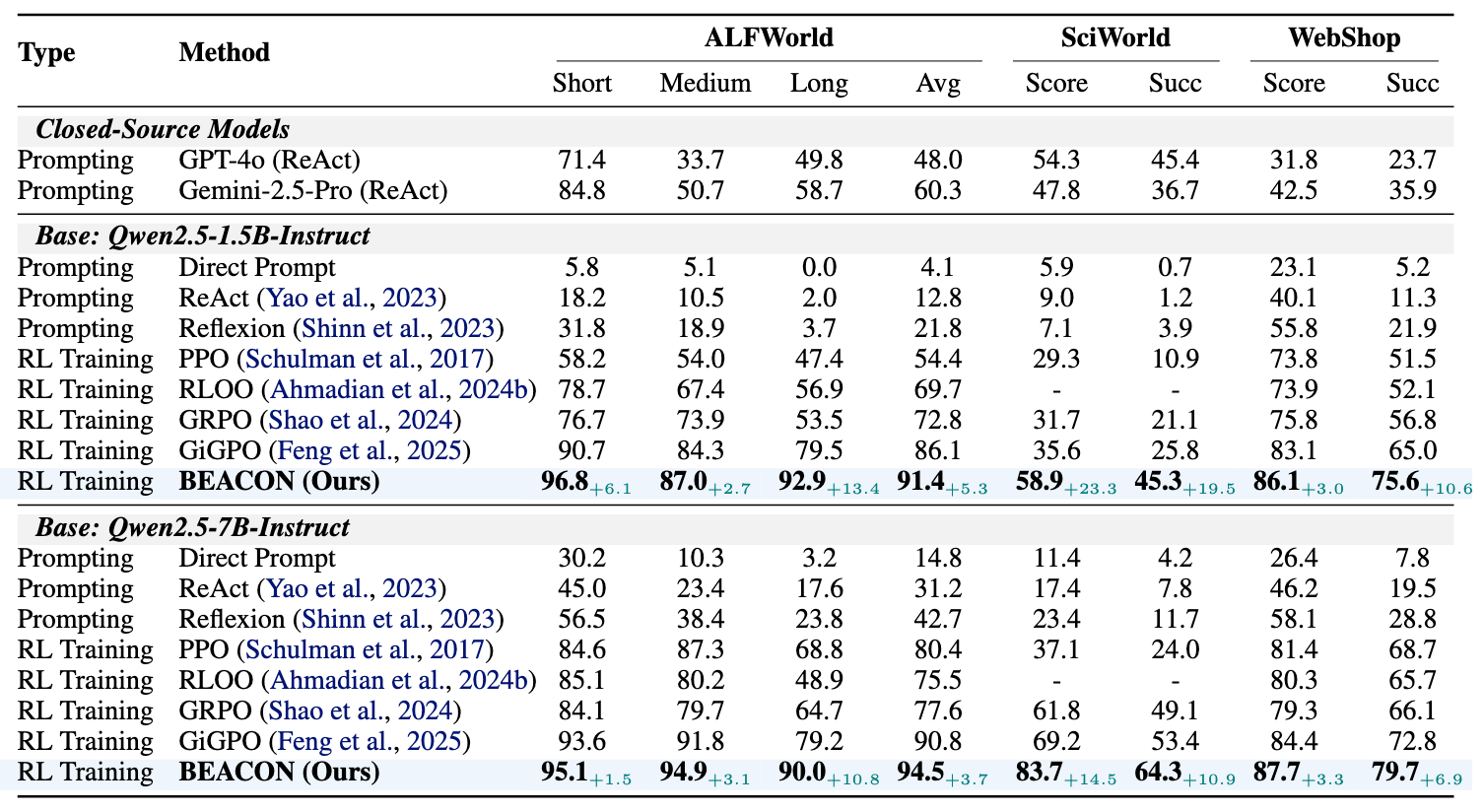
BEACON outperforms GRPO and GiGPO across ALFWorld, ScienceWorld, and WebShop at both 1.5B and 7B scales, using a single set of hyperparameters across all benchmarks.
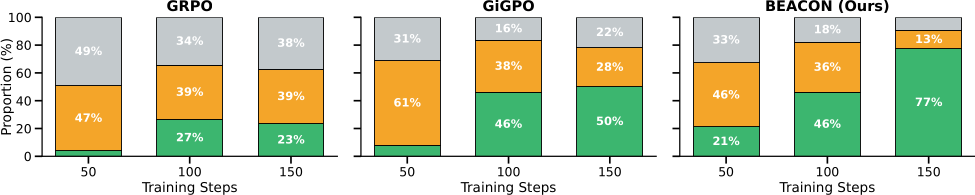
Sample Efficiency. Trajectory distribution during training on ALFWorld. BEACON converts partial successes (orange) into learning signal, lifting effective sample utilization from 23.7% (GRPO) to 82.0%.
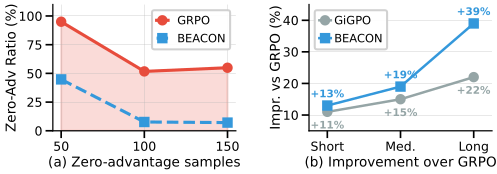
Learning Signal & Horizon Scaling. (a) Zero-Advantage Ratio drops from ~55% (GRPO) to ~10% (BEACON). (b) Relative gains over GRPO scale with task horizon — +14% on Short to +39% on Long for BEACON, while GiGPO plateaus.
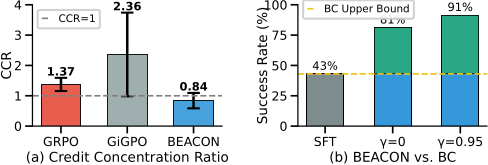
Credit Distribution & Beyond Behavior Cloning. (a) Despite the lowest Credit Concentration Ratio (0.84), BEACON achieves the best performance — preserving graduated credit beats aggressive milestone-only emphasis. (b) BEACON reaches 91.4% vs. 43% for SFT on oracle trajectories — gains stem from policy optimization, not milestone imitation.
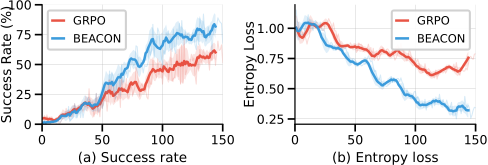
Training Dynamics. BEACON reaches 60% success by iteration 50 — GRPO needs iteration 120 for the same level. Policy entropy decreases smoothly under BEACON, indicating stable refinement from consistent milestone feedback.

Per-Action Credit Assignment. GRPO assigns uniform credit; GiGPO produces counterintuitive signs from state-based grouping; BEACON credits milestones and penalizes errors and detours.
@misc{wang2026milestoneguidedpolicylearninglonghorizon,
title = {Milestone-Guided Policy Learning for Long-Horizon Language Agents},
author = {Zixuan Wang and Yuchen Yan and Hongxing Li and Teng Pan and Dingming Li
and Ruiqing Zhang and Weiming Lu and Jun Xiao and Yueting Zhuang
and Yongliang Shen},
year = {2026},
eprint = {2605.06078},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
url = {https://arxiv.org/abs/2605.06078},
}